There are few tips worthy to try to write better TypeScript in your .net projects as separate files. This article is using EcmaScript modules for client libraries and as well for server TypeScript dependencies.
I believe the classic Multi paged applications still have its place today and in this article I am showing how to use WebPack bundles for individual route.
The idea is to show few concepts.
– TypeScript from NPM
– Client side libraries from NPM
– ES module imports for TypeScript and SCSS/CSS
– Structure of Scripts is similar to structure of Views
– WebPack generates bundles per folders and generates them in wwwroot/ js or css folders
– WebPack generates uses source maps per bundle
– No JavaScript directry in Pages, instead just script reference Page specific generated bundle in wwwroot
The sample application is available at github:
https://github.com/martinkunc/tsbestpractices
- Where to place your TypeScript
Don’t place scripts inside the wwwroot, it is where the destination scripts might go, if you decide so. The source should be placed elsewhere. In .net projects most commonly it is in Scripts folder, React and Angular are using ClientApp in the web solution.
When working with css styles in WebPack, they are imported, so I am placing css in the Scripts folder as well.
2. Use npm to build TypeScript
Because we will use NPM for building and client script dependencies, we will simplify our setup and disable Visual Studio built-in compilation.
I will show how to add node check and module installation your csproj.
First, just create empty package.json inside of your web folder. To do it, execute npm init and then followed with npm install typescript. This will install typescript locally.
https://gist.github.com/martinkunc/3cbb976186184d5aa608739c9ede76f3#file-gistfile1-txt
Then add to your website .csproj following sections to block VS TypeScript, exclude node_modules and installing npm modules if they are missing on build.
Also, I am specifying Scripts as standard SpaRoot property, which React and Angular templates are using. Also, I am placing node_modules inside src/web folder (not inside Scripts). We might use it later for other web dependencies.
https://gist.github.com/martinkunc/fb3c66f9f4fcd38041e06a15c23b15b4
3. Use NPM to download client library dependencies
Most of the client libraries are migrating even client script versions into NPM packages. The system is also offering typescript typings.
I will add jquery and bootstrap libraries with npm. From src\web folder I execute:
npm i jquery bootstrap popper
and types:
npm i — save-dev @types/jquery @types/bootstrap
4. Use EcmaScript Module System
Typescript has evolved from using no module system with namespaces over NodeJs commonjs modules. Now since Ecma 2015 ES modules has become widely supported and we can use them in TypeScript as well. It only requires right configuration.
Inside your tsconfig.json use es2015 or anything newer:
“module”: “es2020”
I am using es2020 to get latest features like async/await.
Like the commonJs modules, ES modules provides modularity in your code. ES modules are getting more support in Web browsers. The Typescript transpiler will convert them still to legal JavaScript according to target specified in tsconfig.json. I am using quite conservative ES5.
“target”: “es5”,
5. Use WebPack for bundling typescript and SCSS
Usually WebPack is used together with SPA applications. It works in a way that looks for all the entries, usually *.js or *.ts files and bundles them in the .js files which are being served to the browser. For the purpose of separating bundles in our Multi Page application, I am creating a bundle per folder. In a fresh solution, we will first install webpack using npm:
https://gist.github.com/martinkunc/d8ccefb2bb4f46e090573794269221c6
Then normally we would create webpack.config.js. Lets look how section to create bundles looks like:
https://gist.github.com/martinkunc/146d6e0acd14ee1ad4b8bda19f0866bc
The entry option on line 10 is being populated by recursive traversing scripts for .ts files and creates a map in form of bundleName : pathToFile.
Because WebPack imports scss using the import statement from ts/js files, it can only search for .ts and I am importing the css from them.
To save css files separatelly in css folder. I am employing MiniCssExtractPlugin. Extracting css as a standalone file will allow us to reference styles explicitly from a Page/View where we need it.
https://gist.github.com/martinkunc/d5d4bbfa60d81bd4254972162a266c57
Also, I want to have jquery available in a global scope. It is normally not needed and the code would work without it, because webpack injects imported reference to jquery using local variable. This is just for the comfort of having jquery in global scope for javascript debugging in the browser using jquery commands. This is being done by using ProvidePlugin plugin.
The sourcemaps are also generated automatically by webpack, but because I am changing the path to /js folder under the wwwroot, and I am creating the bundle by providing full relative path, it would by defualt generate reference to sourcemap including the path. Instead I am just placing name of file, because I am in the folder already. That is the configuration for SourceMapDevToolPlugin does.
6. Use strict TypeScript settings in tsconfig.json and force single quotas by .editorconfig.
The compilerOptions from my tsconfig.json:
https://gist.github.com/martinkunc/a8ae7950c11df487e82a4fad7dd40581
and default formatting for 4 spaces as well as single quotas can be specified in the .editorconfig.
https://gist.github.com/martinkunc/4bc426ad40f87874b92d4f2510f597d4
The whole structure of solution is like this:
https://gist.github.com/martinkunc/e3822c26d8e6ecfacd761b08d67af740
Referring the client script code is being made from the particular Page, or shared component. For example in _Layout I have defined the bootstrap reference.
In the Index.cs.html is only the code related to the page. I can generate html on the server side and then link it to related typescript, which already refers exact element ids. This way I dont need any extra client script code in the views. Additionally I am using .net Core asp-append-version, instead of WebPack generated cache busting hashes. The path to generated .js file is relative to wwwroot, where everything is generated.
The file looks like:
https://gist.github.com/martinkunc/d25bc34099192396be9e510d1bd5734a
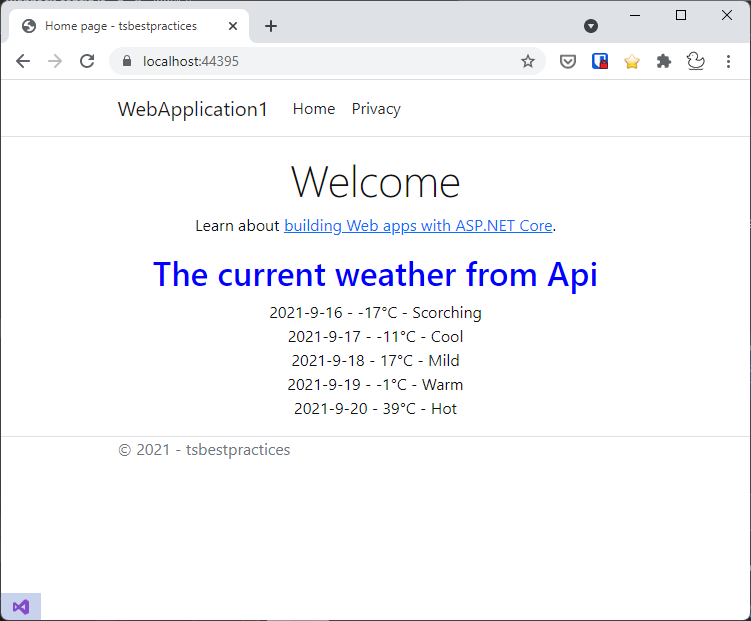
The TypeScript code for index.ts is just calling the weatcherService typescript, which is encapsulating ajax call:
https://gist.github.com/martinkunc/632b1fd1ad39afc575b3e4a51acf8ca5
Summary
The code tries to show a way how to use features of typescript in multipaged application in .net core with some good practices. I hope it makes sense, but if you have some ideas let me know.